Context
The main focus of this paper is the CSRF (cross-site request forgery) attack. Cross-Site Request Forgery stands as a seemingly simple yet persistent threat that has maintained its prominence since its initial discovery in the early 2000s.
Contribution The main contribution of this paper is a comparative study between 16 ML models using various metrics for CSRF attack detection
Approach
This research is based on the dataset named MITCH. The dataset was collected from 5,828 HTTP requests, that were analyzed from 60 widely visited websites. 939 HTTP requests were identified as sensitive
- the dataset contain 6313 records, 54 features, and a mix of legitimate and malicious requests
The dataset was:
- normalized, to ensure that the data was scaled correctly
- split, to create a training set and a testing set
- SMOTE (Synthetic Minority Oversampling) technique was used to balance classes, as fewer example of malicious requests were present
Results
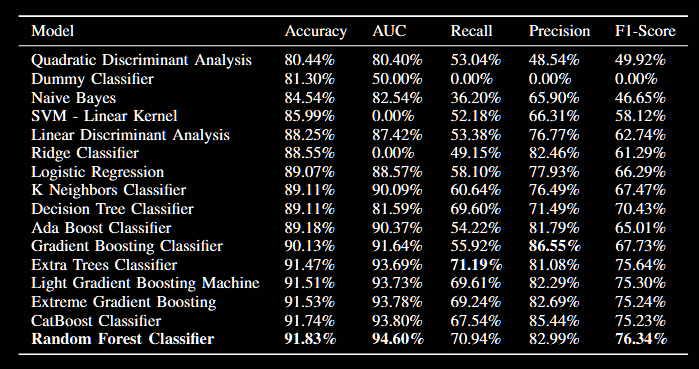
- random forest achieved the best accuracy (91.83%), AUC of 94.60% and F1 score of 76.34%
- in terms of precision Gradient Boosting Classifier scored the highest value of 86.55%
We then select the top 5 models based on their accuracy and performed tuning using 10-fold and 5-fold cross-validation on the data
- The CatBoost classifier achieved the highest mean accuracy, mean AUC, and mean precision. However, it struggled a bit with the mean recall value
- The extra trees model classifier achieved the highest mean recall value and F1-Score