Context
Research into XSS (cross site scripting) prevention and mitigation has continued since XSS was first discovered. Existing approaches
- use static analysis identify XSS vulnerabilities in server-side code
- analyze the use of server-side sanitization functions
- filter out JavaScript code on the server side
- attempt to detect the presence of vulnerabilities from the client’s viewpoint
A different class of solutions attempt to mitigate XSS exploits rather than detect the underlying vulnerabilities. These solutions include:
- XSS filters in browsers (e.g., NoScript for Firefox)
- CSP (Content Security Policy).
- web application firewalls (e.g., ModSecurity)
- server-side HTML sanitizers
These mitigations are widely adopted in practice however it is possible to bypass these defenses (see Scriptless attacks. Stealing the pie without touching the sill)
Insight
- Web apps embed untrusted user input as pure data, such as strings and text. This data is not supposed to be interpreted as code
- Client-side parses mutate the context: suddenly, the string
<script>is interpreted as executable code (we call this “context switch”) - Unintended context switches are the root cause of a series of vulnerabilities, including SQLIA (SQL injection attack), XSS, scriptless attacks, template injection, etc.
- Since the root cause is common, the solution can be the same for all of these attacks
We introduce Context-Auditor, as shell wrapper, an nginx module, a web proxy, and a Chrome extension, to detect content injection exploits in shell commands, HTML, CSS, and JavaScript. We tested our prototypes on reputable testing suites and comprehensive real-world data sets, where Context-Auditor successfully detected and blocked all reflected XSS, scriptless, and command injection exploits in a number of web applications. Context-Auditor demonstrated negligible false positive rate in a live crawl of the Alexa top-1000 websites.
Approach
Parsers (e.g., HTML parser, JavaScript parser, shell parser, etc.) are the entities that eventually parse an exploit, yet they do not know if a context switch is triggered by attacker content or was intended by the developer. With Context-Auditor, we suggest a fundamentally different approach
- we model parsers and detect any context switching caused by attacker-controlled input as a potential content injection exploit
Motivation
- State-of-the-art mitigations attempt to identify characteristics of common exploits as malicious: NoScript and XSS-Auditor operate based on regular expression matching
- ModSecurity searches for known malicious-looking directives inside HTTP traffic
- DOMPurify identifies known potentially harmful characters or patterns
These approaches try to identify attack payload, but they cannot distinguish between malicious and intended payloads because they do not know what is the intended execution context. These approaches operate based on patterns, making them unprepared for unfamiliar exploits. Also, detecting known pattern requires preparation of advanced RegEx (Regular Expression), which is also error-prone.
Ultimately, all these attempts are imperfect because they fail to detect unintended context switch caused by unfamiliar attack payloads.
Context-Auditor
- Context-Auditor analyzes the content generated by web applications to determine the impact of attacker-controlled input on parsing
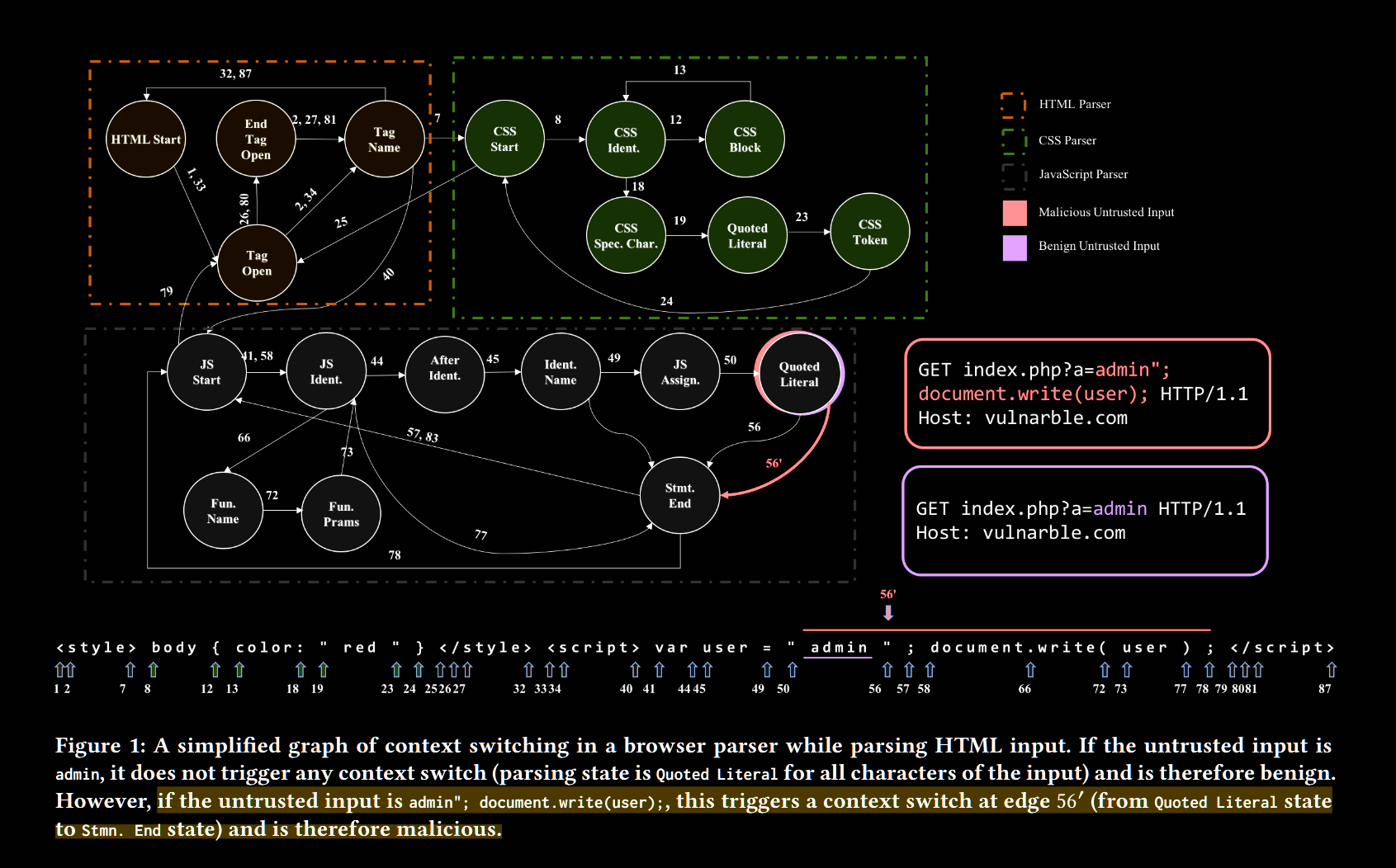
- We designed automata to model context switches in the form of state transitions. These states, named parsing states, includes syntactical and lexical information about the current character, which can determine the type of the token or the statement being parsed. Context is detected by considering language-specific specification and byte-level checks
- Context-Auditor parses everything from the first character of the output until the last character of untrusted data. If a context switch occurs, an exploit is detected
- When an exploit is detected, the user can choose to block the output from reaching its destination
Context-Auditor design
The parsing engine is the core of Context-Auditor. This automaton uses its state transitions to identify context switches, which is the key feature used to detect content injection exploits. We construct this automaton by manually analyzing HTML, JavaScript, CSS, and Bash languages.
Evaluation
We designed seven experiments under different scenarios with different data sets. We used both well-known public data sets and hand-crafted data sets in our experiments. These are all ground-truth content injection exploits that should be detected and blocked by a perfect XSS defense. Because of the lack of publicly available data sets, we also built our own data sets of command injection exploits
- Context-Auditor detected 100% of the malicious payloads
Limits
- False positives. There was one false positive in our experiments, however some circumstances could cause more: For instance, if a blogging application (that allows blogging in raw HTML) reflects the user’s newly created post (which is sent in as an HTTP parameter) in its response, Context-Auditor might report an exploit despite this behavior being legitimate
- Second order XSS: same-context injection, such as DOM-based XSS, cannot be detected by our tool. The root cause of the vulnerability exists in the JavaScript code of the web page and is not due to a context switch
- Transformations of user input. Server-side code or client-side scripts may sometimes perform transformations on user-controlled input (see mXSS attacks. attacking well-secured web-applications by using innerHTML mutations). In this scenario, Context-Auditor cannot detect a context-switch because it has no control over the input transformation
- Stored content injection. Context-Auditor only supports non-stored content injections. This is due to Context-Auditor’s inability to track untrusted input through data stores used by an application. Stored XSS is not detected.
- Syntax errors. Context-Auditor is a research prototype manually built based on languages’ grammars and specifications. We faced issues while parsing malformed HTML and JavaScript codes, which may be acceptable in real-world browsers.